![[レポート]グーグル佐藤一憲氏による『GeminiとVector Searchによる生成的推薦とマルチモーダル意味検索』#cm_odyssey](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1722314205/user-gen-eyecatch/zhdptqia5mvwcycvrsc7.png)
[レポート]グーグル佐藤一憲氏による『GeminiとVector Searchによる生成的推薦とマルチモーダル意味検索』#cm_odyssey
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
クラスメソッド設立20周年を記念し、オフラインイベント、オンラインイベントを複数日にわたって展開するイベント「Classmethod Odyssey」を2024年07月現在、絶賛開催中です。
当エントリでは、2024年07月11日(木)に開催された「Classmethod ODYSSEY 2024 ONLINE」におけるセッション「GeminiとVector Searchによる生成的推薦とマルチモーダル意味検索」の内容について、「本題」のセマンティック検索、RAG、情報検索、生成的推薦を中心にレポートします。
セッション概要
イベント公式サイトに記載のセッション概要情報は以下の通りです。
- 登壇者
- グーグル合同会社 Developer Advocate 佐藤一憲
- セッションタイトル
- GeminiとVector Searchによる生成的推薦とマルチモーダル意味検索
- セッション概要
- 現在のLLM分野ではRAGのようにテキスト生成の品質改善が注目されていますが、LLMの推論(reasoning)の能力はテキスト生成以外のUI/UXにも活用が可能です。このセッションでは検索と推薦のためにLLMを活用する方法を紹介します。
セッション動画
2024年8月1日~2日にかけて横浜でGoogle Next Tokyo '24開催
2024年8月1日~2日にかけてのGoogle クラウドのカンファレンス「Google Next Tokyo '24」がパシフィコ横浜ノースで開催されます。
ビジネス リーダー、イノベーター、エンジニアと幅広い職種を対象としており、セッションの中には、本セッションのスピーカーでもある佐藤 一憲さんとデイヴ・エリオットによる次のセッションもあります
- セッションタイトル
- Era of Gemini:生成 AI の力をエンタープライズ システムに活用する方法
- セッション概要
- Google の Gemini 1.5 Pro/Flash は、大規模マルチモーダル モデルです。Mixture-of-Experts アーキテクチャにより効率性と性能を向上させ、最大 200 万トークンのコンテキスト ウィンドウでテキスト、コード、画像、音声、動画を扱えます。本セッションでは、Gemini モデルを情報検索と推薦に活用したエンタープライズ システム構築について解説します。
ぜひ、ご参加ください
マルチモーダル意味検索(セマンティック検索)とは?
RAGを作るにせよ何にせよ、LLMのイノベーションと同時にエンべディングとベクトル検索のイノベーションが同時に起こっています。
メルカリの600万件の画像データに対してVertex AIを利用すると、検索文章の意味で画像検索できます。
「踊っている人のコップ("cups with dancing people")」で検索すると、検索語の意味をベクトルで表現し、600万件の画像からこれに似た画像を瞬時に(20ms)検索できます。
テキスト、ラベル、カテゴリといった画像のメタデータを一切利用せず、画像そのものとVertex AIのエンべディングAPIだけを使ってベクトル検索しているだけです。
昔のCNNのようなビジョンモデルではない、人間の目と同じような理解力をもったLLM、より正確にはここ数年で大きく発展したVision Language Model(VLM)という常識を持つビジョンモデルを使った意味検索が行われています。
Embeddingとベクトル検索のおさらい
LLMのイノベーションと並行してエンべディングとベクトル検索のイノベーションも同時に起こっています。
Spotify、TikTok、Instagramなど、次から次へと推薦される今どきのユーザー体験のほとんどはエンべディングとベクトル検索で実装されています。
従来の検索の99.9%は、表形式データ(タビュラーデータ)を使って、キーワード検索したり、カテゴリやラベルで検索しています。
Google検索、Gooogle Mapで店さがし、SpotifyやTikTokの次々にコンテンツが推薦されるユーザー体験はディープラーニングモデルが作ったエンべディングを使って、コンテンツの意味を表現し、検索・推薦システムを作ることで、今どきのコンシューマー向けのインターネットサービスのUXは実現されています。
Googleはこのセマンティック検索は2015年ごろから導入しています。
エンべディングとは
単純化すると、エンべディングはAI(ディープラーニングモデル)が作るベクトル空間であり、ベクトル空間は文章、画像、音声といったコンテンツの意味を表せ、「意味の地図」とも言えます。
エンべディングにより、あるコンテンツを[0.1, 0.2, 0.3]というようなベクトル空間の座標で表せます。
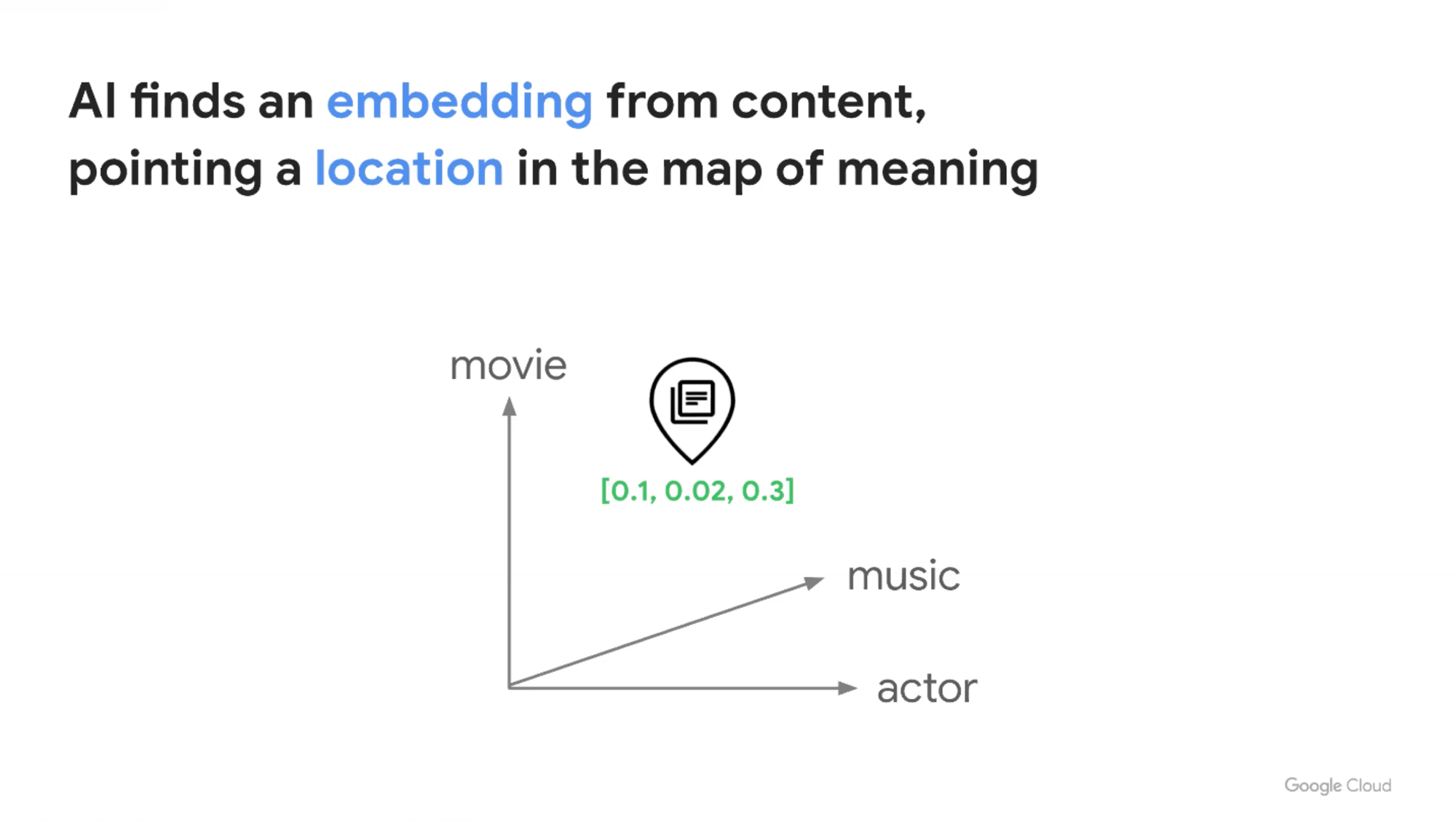
エンべディングにより、コンテンツのエンべディングの周りを探すだけで、似た他のコンテンツを瞬時に見つけられます。
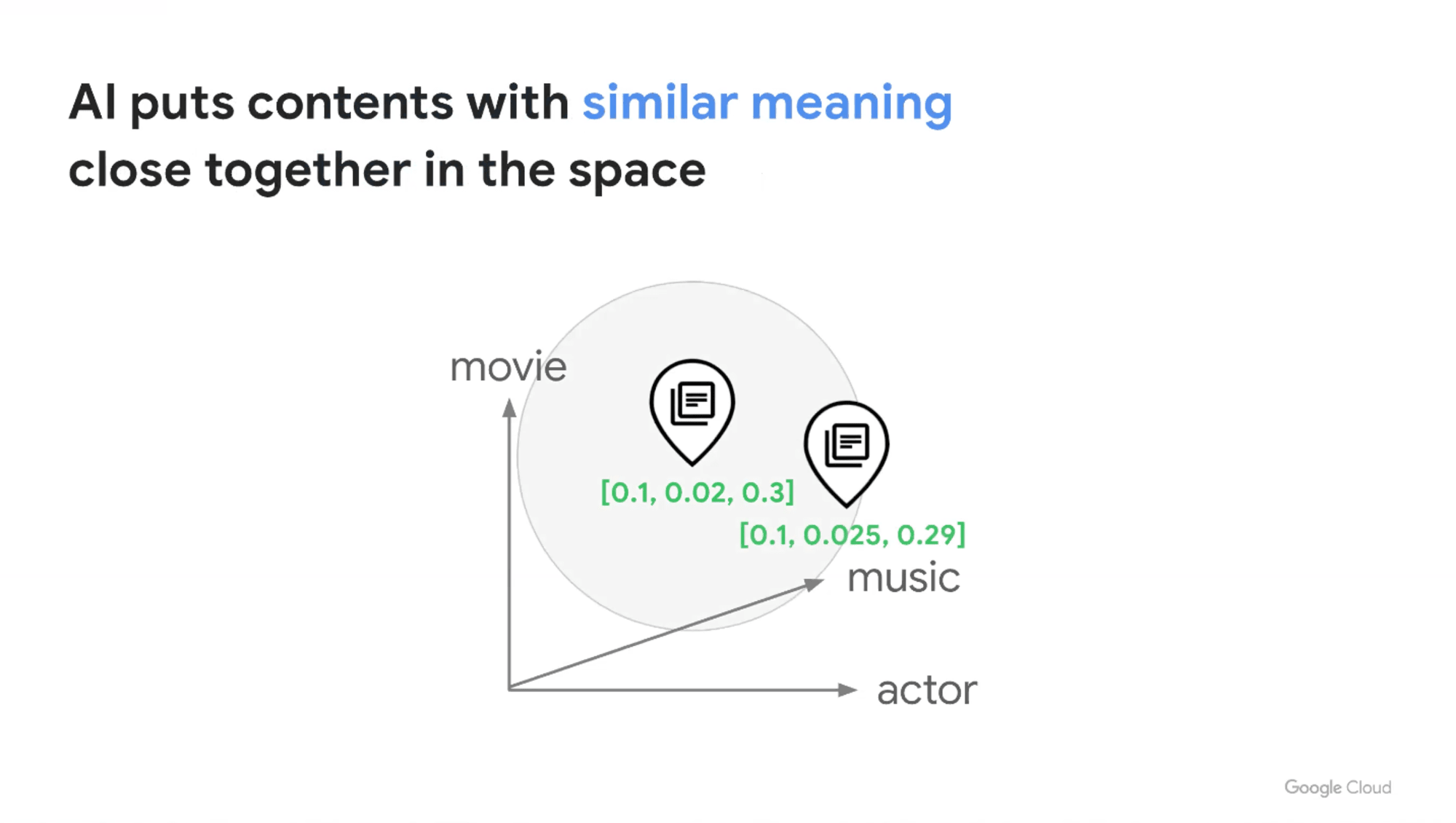
ベクトルであれば何でもよいわけではなく、画像のピクセルイメージをベクトルで表現したり、文章をOne-Hotエンコーディングでベクトル変換する(疎ベクトル)といったような意味のないベクトルでは駄目で、比較的低次元(10^2~10^4)のベクトルの中に意味を凝縮したベクトル(密ベクトル)がエンべディングです。
エンべディングはコンテンツの類似検索だけでなく
- 製品の特徴
- ユーザーの特性(プレミアムなユーザーか)
- ユーザーの行動(Google Shoppingがやっている)
- 工場の中のセンサーのシグナルから故障しそうなデバイスを検出
といったありとあらゆるビジネス的な意味検索も、エンべディングモデルを用意すれば、実現可能です。
ビジネスのエンティティ(ビジネス的意味)を表現するものとして、リレーショナルデータベースのレコードからエンべディングが非常に大きな意味を持つようになりつつあります。
マルチモーダル・エンべディング
テキストだけのエンべディングではなく、
- 画像
- テキスト
- ビデオ
等が同じエンべディング空間を共有しているのがマルチモーダルです。
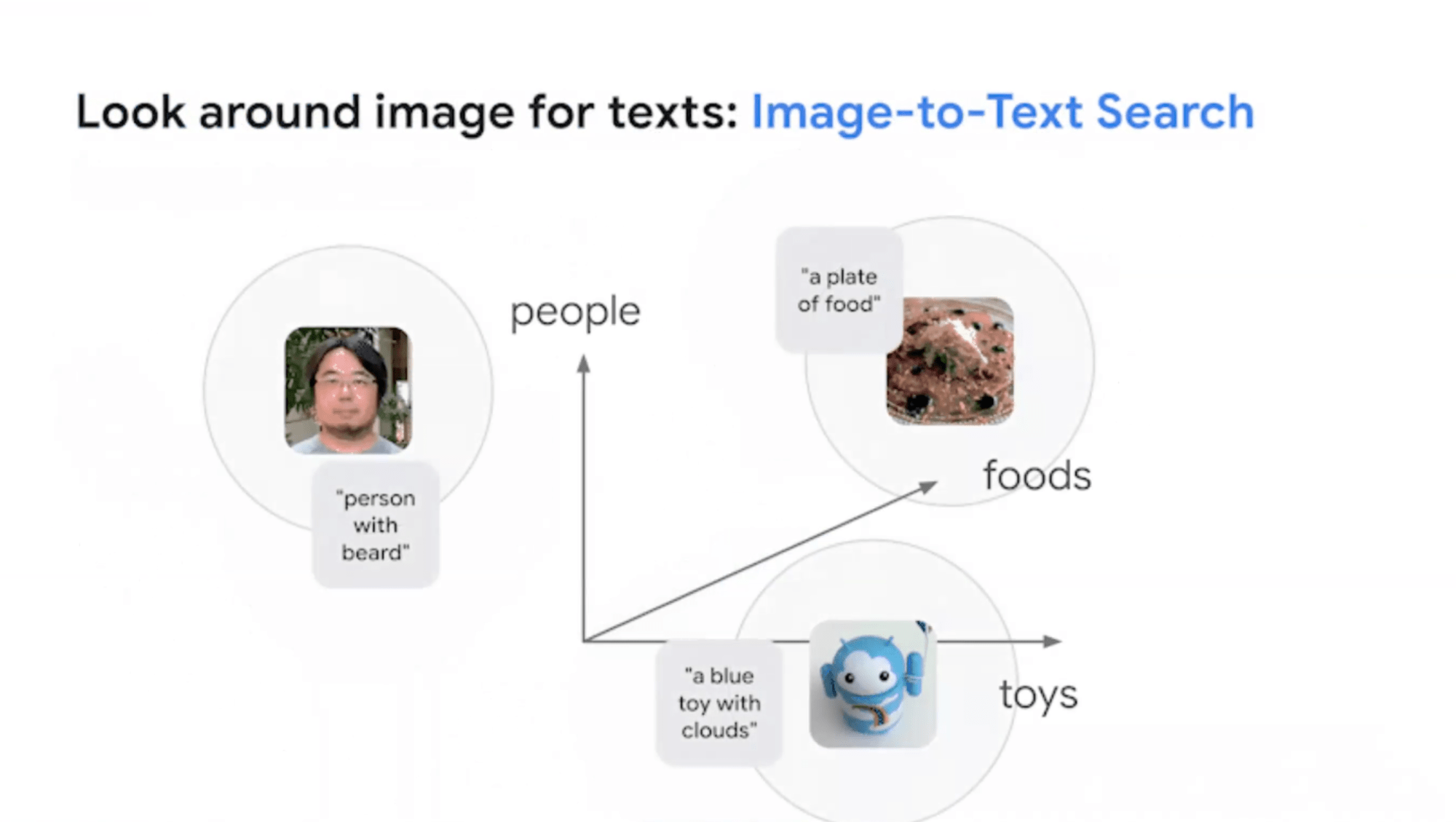
画像のエンべディングの周りを探すと、同じ意味を表す文章が見つかったり、文章のエンべディングの周りを探すと、同じ意味を表す画像が見つかる、というようなマルチモーダル意味検索を実現できます。
冒頭のメルカリの画像検索は画像とテキストのマルチモーダル検索の例です。
Google 検索では2015以降は意味検索を使っているし、Google PhotoやGoogle 画像検索なども同じ技術を使ってますが、ブレークスルーはLLMとVision Language Model(VLM)の登場です。
Stable DiffusionやMidjourneyのブレークスルーの背景にはClIP(Contrastive Language-Image Pre-Training)というモデルがありました。
従来のビジョンモデルの学習では、人間がラベリングして学習していましたが、文章のエンべディングで画像のラベルをつけるようにした、つまり、文章のエンべディングと画像のエンべディングの関係性を学んでいるのがCLIPの画期的なところです。
これまでのCNN(Convolutional Neural Network)のエンべディングは見た目、模様、形が似ているものは検索できましたが、「コップである」というように、人間が見た時に認識する情報(言語的な意味)と画像的な特徴の関係を学習しているのが、ここ3年位で実用化された、今どきのVLMの特徴です。
VLMでは、Googleのロゴはどういう色なのか知っているという常識に基づいて、「Googleのロゴの色のコップ」という文章で画像検索でき、OCRも一切不要です。
Google検索の検索技術で実現するRAG
ここからは、Google検索が培ってきた検索技術でRAGを実現する話です。
RAGのためには、意味検索だけでは足りず、ハイブリッドサーチなど、いろんな技術が必要です。
ユーザーがLLMに直接回答させると、ハルシネーションを起こすことが実開発やエンタープライズ用途で導入するボトルネックになっています。

それなら、企業のデータベースで検索して、その検索結果をプロンプトとして読み込ませて回答させると、ハルシネーションが減るという発想から、RAGが世の中を席巻しています。
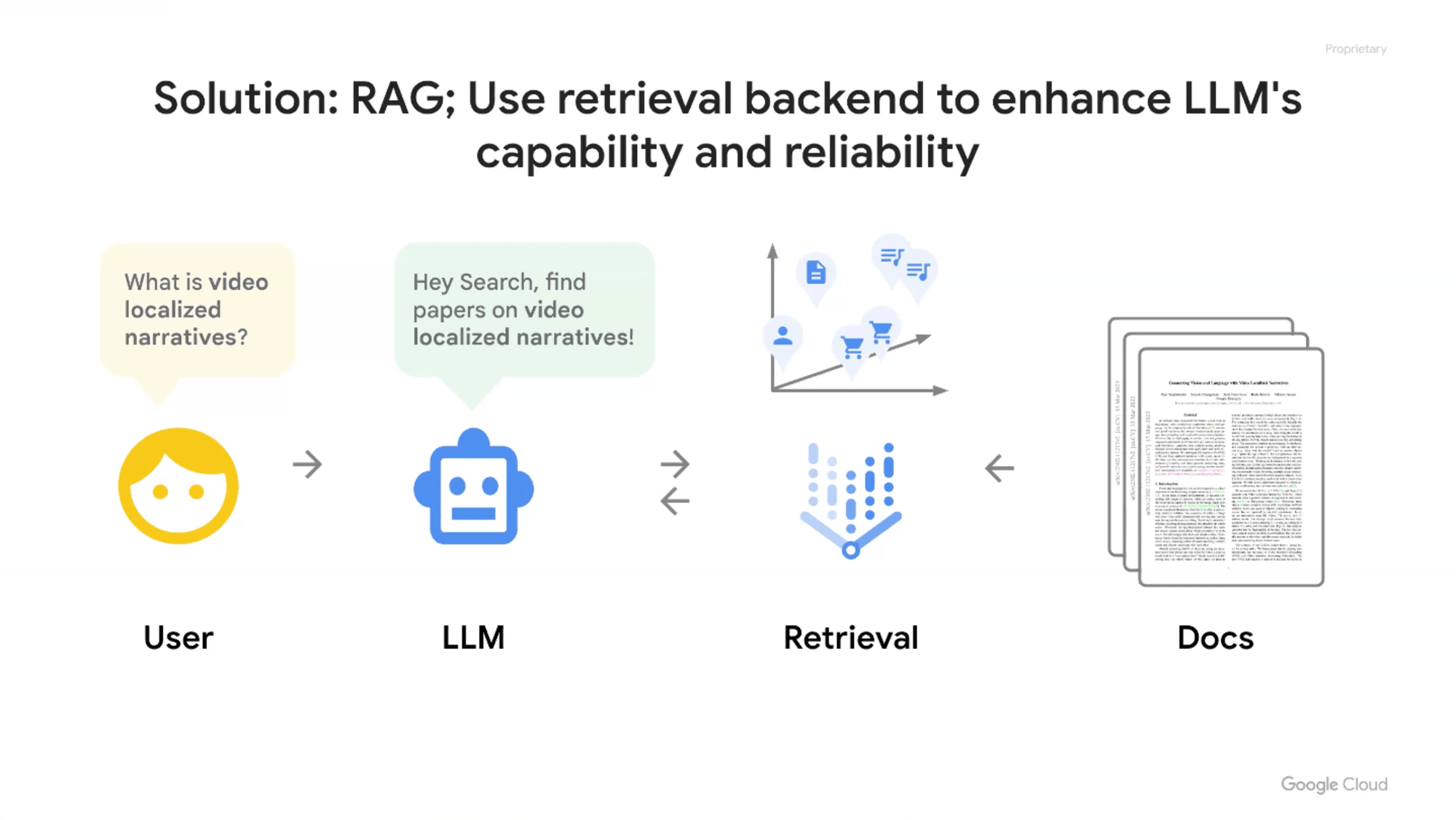
RAGのRはRetrievalと言っても、中身は検索エンジンです。
RAGの検索技術ではセマンティック検索、キーワード検索、両者を組み合わせたハイブリッド検索、グラフデータベースのRAGを使う、などいろいろありますが、RAGの検索部分(Retrieval)はLLMとは全く関係なく、そこで使う検索エンジン(Retrieval)をどう実装するのかは完全に独立したテーマです。
ECサイトの製品検索やWeb検索など、検索エンジンの時に求められたものと同じ検索品質がRAGにも要求されます。つまり、RAGを作るというのは、企業における情報検索の基盤を作るのと全く同じ難しさが要求されるので、グラフデータベースを使うと簡単になるとか、意味検索を使うと簡単になるといった、そういう問題ではありません。
RAG界隈で出てきている、チャンクする、クエリ拡張、ハイブリッド拡張、グラフデータベース、リランキングといった話題は、情報検索各社が過去数十年にわたってずっとやってきた、一筋縄ではいかない情報検索の苦しみを、RAG開発者が現在味わっているのが現状です。
こういうAdvanced RAGと呼ばれるような技術要素を全て実装するのは大変なため、すべての課題を解決できないかもしれないが、これら課題と向き合ってきたGoogleの検索技術を使ってRAGを作ろうというのがGoogle CloudのVertex AI Searchです。
Google検索がこれまで培ってきた検索技術
- ドキュメントをパースチャンクに分ける
- チャンクをトークンに分ける
- 意味のあるエンべディングを作る
- トークンとエンべディングのインデックスを作る
- 両者にクエリーをかけて、ハイブリッド検索
- 検索結果をマージしてリランク
これらはGoogleが一番投資してきたところなので、それをお客様に提供するのがVertex AI Searchです。
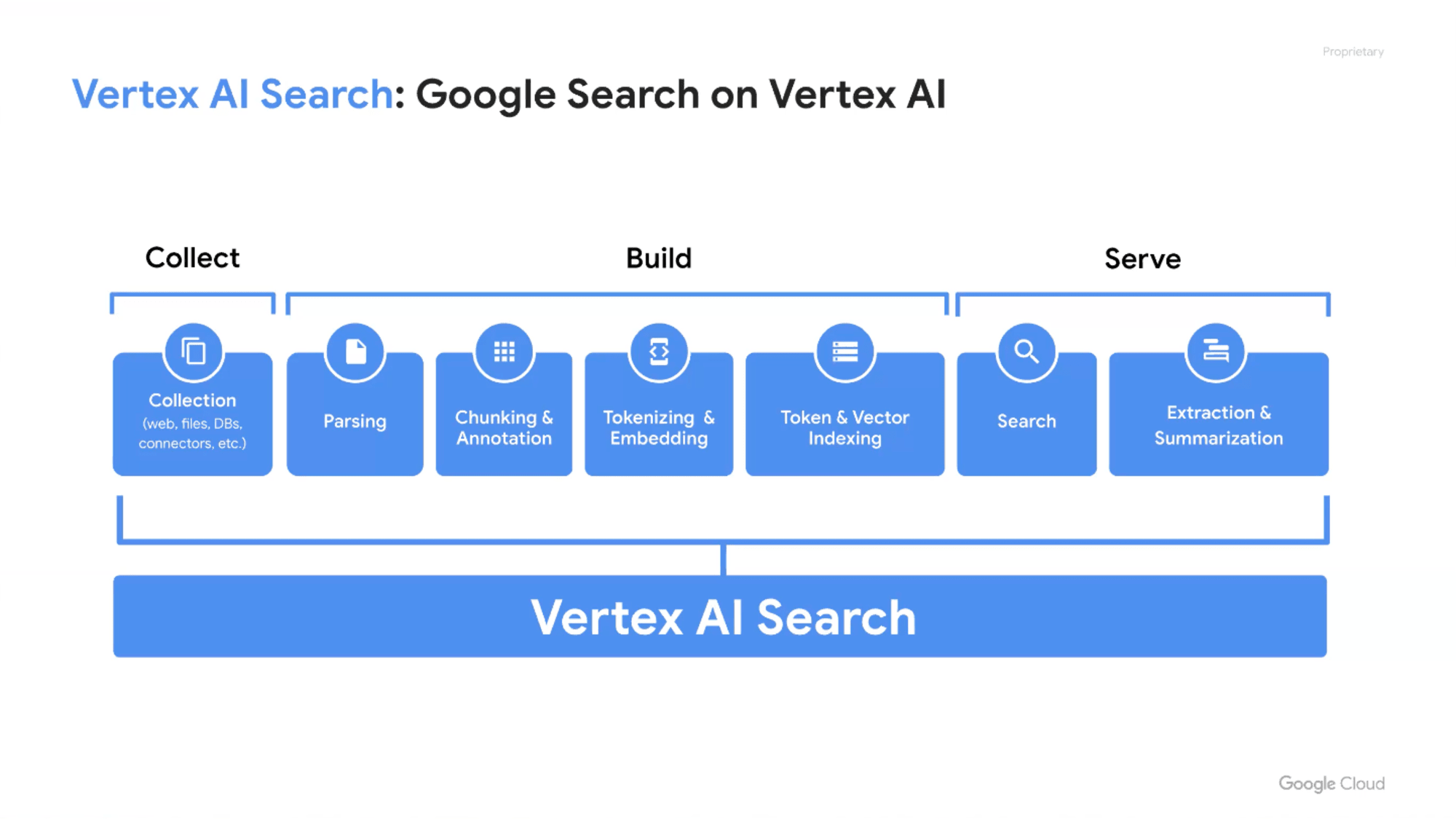
Vertex AI Searchは美味しいところをAPIとして提供しているので、フルスクラッチ開発に比べて、ブラックボックス化されていたり、カスタマイズできる余地が限定されるといったデメリットもありますが、費用対効果、開発期間の短さ、開発コストなどを考えると、十分に効果的なソリューションとして検討できるのではないでしょうか。
セマンティック検索の最大の課題は、9割のRAGはナイーブに類似検索をやっているだけであり、検索品質の壁に当たっていることです。
"The question is not the answer.(質問は答えではない)"という言葉があるように、答えの文章と質問の文章は意味がぜんぜん違います。それなのに、例えば「空はなぜ青いのか?」という質問文のエンべディングをそのままベクトル検索してコンテンツがうまく見つからず、検索品質の問題に苦慮しています。
この課題は情報検索(IR)の世界では何十年も研究されてきたのに、9割方のRAGはそこにたどり着けていないというのが現状です。
Googleはクエリーと検索対象のドキュメントの間に非常に大きなギャップがあると認識しており、2015年のRankBrainや2018年のNeural matchingというようにGoogleは何年も前に解決済みです。
クエリの意図を理解して、コンテキストを推測して、対応するドキュメントを検索するのがGoogle検索です。
クエリとドキュメントの間のギャップを埋めるためにGoogleはディープラーニングモデルをずっと頑張って作ってきました。
これを世界中の何十億人というユーザーに、無償で安く早く使えるためのインフラをハードウェアからチップからインフラから全部作ってきたのがGoogleのIRの歴史であり、これが今の9割のRAGは欠けています。
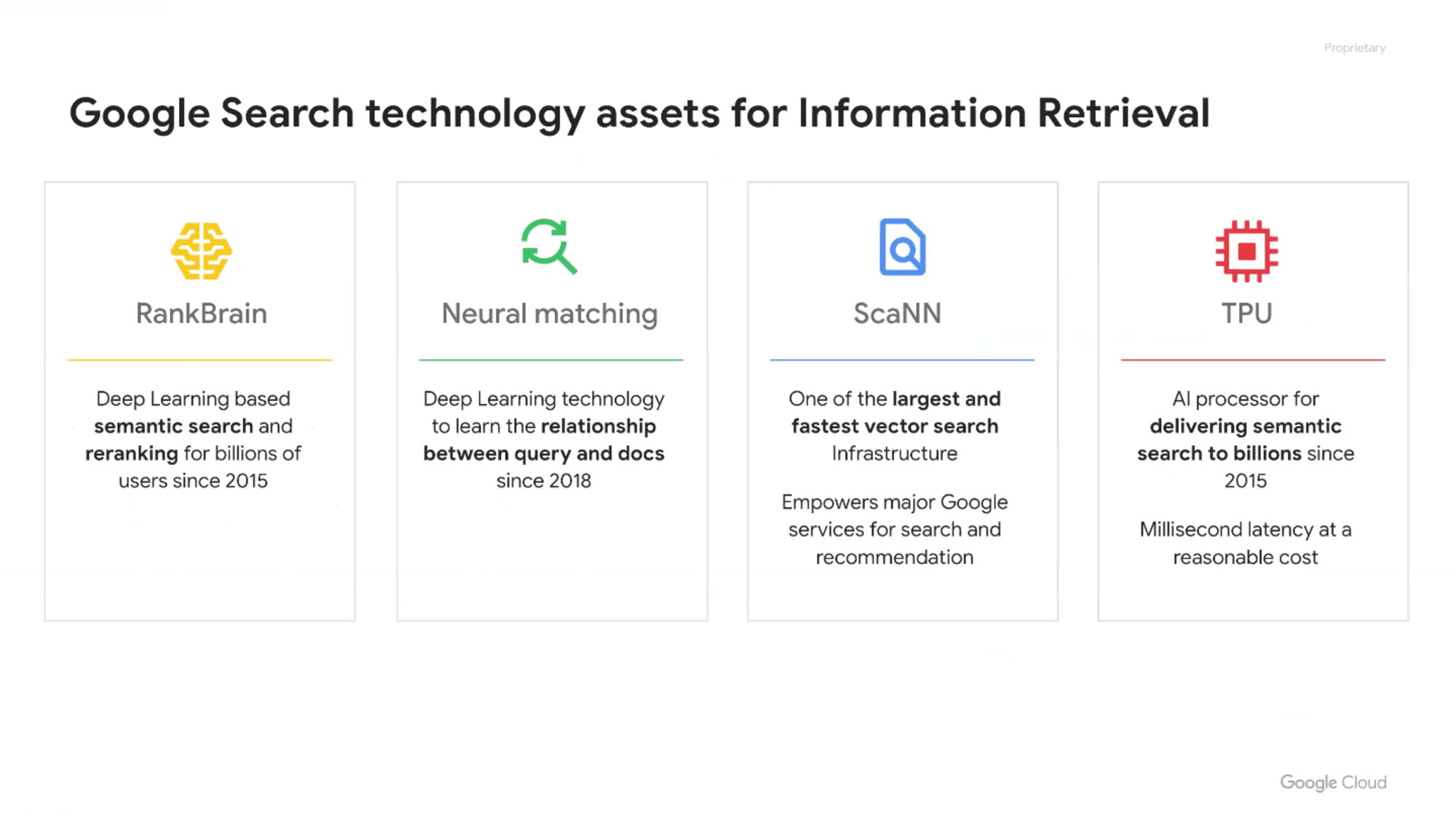
このRankgBrain、Neural Matching、それを支えるベクトル検索は、おそらく世界で最も大規模に運用されているベクトル検索です。なぜ、こんなに高速にベクトル検索やエンべディングを生成できるのかというと、専用のプロセッサー(Tensor Processing Unit;TPU)をゼロから作っているからです。
TPUはGoogle Cloudのために開発されたプロセッサーではなくて、もともと(第1世代)は論文にあるようにGoogle検索の意味検索を最大の用途として開発されました。
2015年にこれからはGoogle検索はキーワード検索だけでなく、ハイブリッド検索になると決めた時に、大量のディープラーニングモデルモデル・大量エンべディングを使って、高速な意味検索(ScaNN)をやると決めた段階で、GPUではスケールしないし、ペイしないので、専用の桁違いに安く、ディープラーニングの推論・学習をやるための専用プロセッサーを作るところからやって、Google検索の意味検索を実現しています。
これと同じことを、一般企業がやるのは現実的ではありません。
これらをまるっと簡単に安く提供するのがVertex AI Searchというプロダクトです。
Grounding in Gemini
Vertex AI Searchを使って簡単にRAGを作れるのが最近リリースされた Grounding in Gemini です。
データセットを登録し、Groundingオプションをオンにて、ポチポチするだけで、事実に基づいた(=ハルシネーションを防ぐ)RAG検索ができます。更には、ネットに一般公開されている情報であれば、Google検索結果をRAGのデータソースにできます。
このような非常に簡単なRAGシステムであれば、自分でチャンキングやハイブリッド検索やグラフなどといった難しいことを考えなくても、Google検索やVertex AI SearchといったトップクラスのIR技術を使って、簡単にRAGシステムを作れます。
Geminiによる生成的推薦とRAG
今後は、生成的推薦が重要になるのではないかという提案が次のテーマです。
「生成AI」という言葉はミスリーディングです。ある論文によると、生成AIのパラメーターの8割は推論に使われており、理解(エンべディングの生成)や生成(アウトプット)はそれぞれ10%しか使っていません。

つまり、今の生成AIの一番肝心なところは生成するところではなく、人間の大人と同じように「こういうふうに聞かれたら、こういうふうに答えればよいよね」というような推論(reasoning)の部分にあり、そのためにあれほどたくさんのGPUが必要です。
推論が重要となると、生成AIはチャットボットのように文章を生成するだけでなく、ロボットをコントロールしたり、自動運転にも使えます。同様に、推薦システムに推論の機能を使えば、意味検索のクエリーに対して、単純に意味が近いものを探すのではなく、Google検索がこれまでNeural MatchingやNeuralBrainでやってきたような、クエリーと対象となる検索結果のギャップを埋めるための推論にLLMを使うのが面白いのではないでしょうか?
「冬用のあったかい服」という問い合わせに対して、LLMの高級な推論の機能があるのだから、人間の店員さんがやるような
- (タイプ)あったかいジャケット、サーマル・レギンス
- (アクティビティ)スキーの服、走るための服
- (スタイル)カシミアのセーター
という時に、ユーザー(お客様)はどういう服を探しているのか、クエリーと結果を埋めるのが、生成AIの本来の使い方ではないでしょうか。
これがGenerative Recommendationという考え方であり、去年あたりから推薦システム界隈でホットな話題となっています。
参考 : Generative Recommendation : LLMを活用した推薦システム | Wantedly Engineer Blog
このアイデアをベースにしてGeminiを活用したデモが Infinite Natureであり、Google Cloud Next ’24 や カンヌライオンズ国際クリエイティビティ・フェスティバルで展示されました。
2024年8月1日~2日にかけて横浜で開催されるGoogle Next Tokyo '24でも同様のデモや発表も行われるため、ぜひご参加ください。
感想
Googleは屋台骨である情報検索(information retrieval)に何十年も膨大な投資をしてきました。
近年のLLMの発展で生成AIやRAGやベクトル検索といったキーワードをよく耳にするようになり、その流れでなんとなくRAGシステムを作ってみたものの、検索の精度で行き詰まった人は多いのではないでしょうか?。
RAGのRetreival部分(情報検索)は独立したコンポーネントであり、検索精度の大きな課題である質問とドキュメントのギャップを埋めるクエリ拡張の推論にLLMを応用する余地が大いに残っているという主張にはなるほどと思いました。
情報検索の技術要素を勉強して自分たちで作り込むのも楽しいですが、ビジネス観点では、難しいところを隠蔽して誰でも簡単に素早く情報探索できるVertex AI Searchのようなサービスを試すのが多くのユーザーにとって現実解の一つと思えました。









